|
||||||||||||
|
||||||||||||
| Какой брокер лучше? Альпари Just2Trade R Trader Intrade.bar Сделайте свой выбор! | ||||||||||||
| Какой брокер лучше? Just2Trade Альпари R Trader | ||||||||||||
Поиск с приоритетом шаговПоиск с приоритетом шагов сканирует в одно время одну переменную, а выбранное значение сохраняется постоянным для каждого из следующих сканирований, в целях снижения отрицательного воздействия на эффективность. Рассмотрим предыдущий тестовый набор из 4 переменных:
То, что по временным затратам делало решетчатый поиск непригодным для проведения данного теста, то для метода поиска с приоритетом шагов вполне по силам. Тестовый прогон будет состоять всего из 166 тестов (15+49+51+51=166), а это совсем другое дело. Как это делается? И в чем недостаток этого метода?
Первая переменная считается наиболее важной и сканируется первой, при постоянных значениях каждой из трех остальных переменных. Константы для трех других переменных могут выбираться случайно или априорно. Так называемый «серединный» подход использует в качестве констант середину каждого диапазона сканирования. Первое сканирование будет таким:
В первом сканировании все возможные значения МА1 оцениваются при постоянных значениях МА2, VB1 и VB2. Каково значение допущения, что МА1 является самой важной переменной? Первый тест будет определять оптимальное значение МА1, которое затем будет сохраняться постоянным в последующих сканированиях второй, третьей и четвертой переменной. Например, допустим, что первый шаг этого теста определил топ-модель со значением МА1, равным 5. Следующий шаг, сканирование второй переменной, будет проводиться с помощью следующих комбинаций:
Это сканирование, в свою очередь, определит оптимальное значение для МА2. Это оптимальное значение, например, 29, в дальнейшем будет использовано в третьем и четвертом сканированиях. Два преимущества поиска с приоритетом шагов – скорость и оценка относительного влияния каждой переменной. Наиболее значимая переменная модели – та, которая оказывает наибольшее влияние на эффективность. Допустим, что сканирование МА1 дало следующие результаты:
В этом же тесте сканирование VB1 дает следующие прибыли и убытки:
Различные значения МА1 привели к серьезному изменению прибылей и убытков, в то время как различные значения VB1 привели к небольшим изменениям. Вывод из этого – в данной модели МА1 является более значимой переменной, чем VB1. Это может привести к двум следствиям. Возможно, полосы волатильности (volatility bands) слабо помогают данной торговой модели. Возможно, их можно убрать. При разработке модели действует принцип «меньшее-лишнее». Безусловно, учитывая небольшое изменение, которое давали разные значения переменной VB1, нет достаточных причин проводить более глубокий поиск. Учитывая небольшое число тестов, требуемых для выполнения этого поиска, затраты на него невелики. С другой стороны, недостаток скрупулезности, вызываемый очень ограниченным диапазоном поиска с приоритетом шагов, в некоторых случаях может оказаться большим недостатком, особенно если при пошаговом поиске обнаруживается, что каждая переменная существенно влияет на эффективность. Поиск методом прямого спуска (Direct Descent Search) Поиск методом прямого спуска – один из многих очень быстрых методов направленного поиска. Главное отличие направленного поиска от поиска на решетке – это то, что может быть названо «информированной избирательностью» («enlighten selectivity»). Поиск на решетке последовательно рассматривает каждого кандидата в тестовой группе. Направленный поиск отыскивает путь к наивысшей эффективности в тестовой группе и доводит его до логического завершения. В течение этого он отбрасывает эффективность, которая меньше уже найденной, отдает предпочтение лучшей эффективности и двигается в этом «направлении» в рамках набора тестов или модельного пространства, как его иногда называют. Графически эта идея представлена на Рисунке 5-2.
Достоинство «информированной избирательности», встроенной в методы направленного поиска, в том, что обычно она делает эти методы очень быстрыми. Метод направленного поиска может потребовать расчета всего 5-10% всех возможных моделей, в то время как метод поиска на решетке рассчитывает число всех комбинаций. Поиск методом прямого спуска может также страдать недостатком скрупулезности. Не проверяя каждую модель, претендующую на роль лучшей, этот метод сопряжен с риском пропустить топ-модель. Поиск методом градиентного спуска также требует непрерывности модельного пространства. Этот метод может ошибочно выбирать локальный максимум в качестве глобального максимума. То есть, он может выбрать топ-модель для конкретной области пространства переменных и остановить поиск; следовательно, он упустит топ-модель для всего пространства. Сочетание локального решетчатого поиска с методом направленного поиска – одна из вариаций на тему комбинирования некоторых лучших моментов обоих методов способом, призванным компенсировать слабые стороны каждого из них. Этот метод быстрее, чем поиск по узлам решетки, и медленнее, чем чистый направленный поиск. Он менее тщателен, чем поиск по узлам решетки, и более тщателен, чем направленный поиск. Он менее подвержен попаданию в локальный максимум, чем направленный поиск.
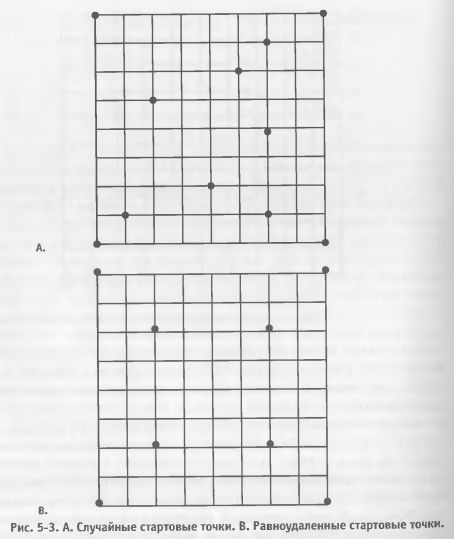
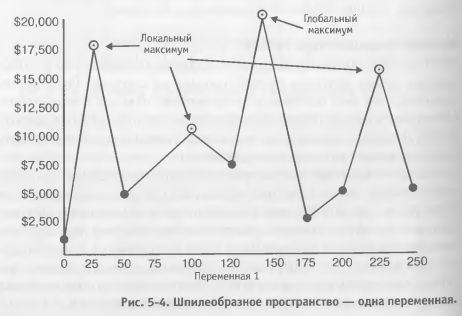
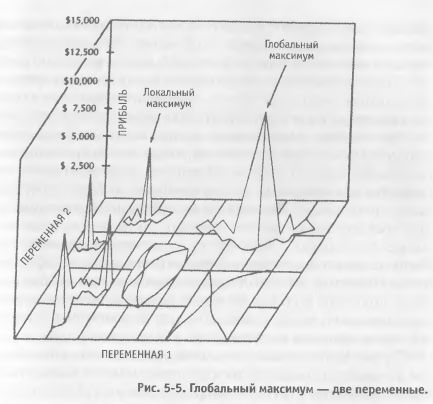
Многоточечный направленный поиск отбирает группу различных стартовых точек. Они могут выбираться несколькими способами, например, случайным выбором из пространства переменных или путем деления пространства переменных на равные по величине сегменты и выбора в качестве точки входа «центра» каждого сегмента. (См. Рисунок 5-3). Затем данный поиск входит в пространство переменных в своей первой точке входа и ищет лучшую модель в этой области. Если данный поиск после выполнения определенного заранее заданного числа шагов не дает кандидата, удовлетворяющего критерию эффективности, поиск на решетке в локальной области прекращается и перемещается на следующую стартовую точку. Если же данный кандидат действительно удовлетворяет минимальному критерию эффективности, то далее выполняется поиск на решетке в этой локальной области модельного пространства. Мы находим топ-модель и запоминаем ее. Затем поиск переходит к следующей стартовой точке, и этот процесс повторяется. Если модель, удовлетворяющая критерию эффективности, найдена, то в этой области выполняется поиск на решетке, и топ-модель, обнаруженная здесь, сравнивается с топ-моделью, найденной в предыдущих поисках. Если она лучше, то становится новой топ-моделью. Если же она не столь хороша, то мы ее отвергаем. Многоточечный направленный поиск продолжается таким образом до тех пор, пока не будут исследованы все точки входа. Этот комбинированный метод поиска быстрее, чем поиск на решетке, и медленнее, чем чистый направленный поиск. Он более тщателен, чем чистый направленный поиск, и менее тщателен, чем поиск на решетке. Он с меньшей вероятностью примет локальный максимум за глобальную топ-модель, чем чистый метод направленного поиска. Аналитик может выбрать столько стартовых точек, сколько сочтет целесообразным; в своем крайнем случае, когда каждая точка решетки является стартовой точкой, данный метод становится аналогичным методу поиска на решетке, но еще более медленным. Методы генетического поиска Методы генетического поиска – наиболее продвинутые и сложные из новых методов, разработанных на сегодня. Есть свидетельства, что они быстрее и достоверней, чем все предыдущие. Описание подробностей их действия не входит в рамки данной книги. Однако в связи с их превосходством знание о их существовании может оказаться полезным. Методы генетического поиска являются методами направленного поиска, но включение «мутаций» (то есть нестандартных случайных шагов в области пространства переменных, отклоняющихся от пути направленного поиска) снижает вероятность выбора локального максимума в качестве глобальной топ-модели. Поскольку для пространства торговых моделей характерно обилие экстремумов, надежность генетических методов делает Их перспективными в исследовании торговых моделей. Общие проблемы методов поиска У методов направленного поиска в целом есть несколько недостатков. Поскольку метод направленного поиска не оценивает каждого кандидата, существует риск недостаточной точности. Направленный поиск гораздо более тщателен, чем пошаговый поиск. Но он менее точен, чем поиск на решетке. Опыт многоточечного направленного поиска в сочетании с методом поиска на решетке свидетельствует, что таким комбинированным методом можно находить модели, входящие по эффективности в лучшие 10-20%. Вторая и, возможно, более серьезная проблема методов направленного поиска состоит в том, что они не всегда гарантируют нахождение истинного пика, называемого глобальным максимумом, но могут ошибочно принимать за него локальный максимум. Глобальный максимум – это самая эффективная модель во всей тестовой группе, а локальный максимум – самая эффективная модель в «локальной области» тестовой группы (см. Рисунок 5-4).
Ошибочное принятие локального максимума за глобальный может происходить по причинам, связанным с особенностями метода поиска и «формой пространства переменных». У такого метода будут возникать проблемы «пикообразной» переменной, группой моделей с очень большим числом пиков эффективности, окруженных глубокими впадинами. Рассматривая применение методов направленного поиска, важно помнить об этих проблемах.
|
||||||||||||

|
||||||||||||
|
|
||||||||||||











 от лучшего Форекс-брокера – компании «Альпари». Минимальный контракт – от $1, экспирация – от 30 сек. Типы опционов: «Выше/Ниже», «Касание», «Диапазон», «Спред», «Экспресс», «Турбо». Альпари – один из наиболее надежных Форекс-брокеров. Более 2 млн. клиентов из 150 стран. На рынке – с 1998 года.")